
Data-driven insights: how AI is transforming industrial processes
By Heiko Petersen and Patrick Meade Vargas - ABB Process Automation, and Ruomu Tan - ABB Corporate Research Process Automation
Monday, 04 August, 2025

Although most of the underlying mathematics of control systems stems from the 1960s, it has only recently become feasible to apply some algorithms in real time.
Nowadays, artificial intelligence (AI) seems omnipresent. It is a common topic of conversation, bookstores are flooded with literature about it, and few applications seem to do without it. But considering the sheer amount of hype, one may wonder why AI is still so seldom used in the process industries. Or could it perhaps be that it is already used, but just not recognised as such?
Generally, a system is considered to be AI-driven when it performs tasks typically done by humans, such as visual perception, decision making, speech recognition, and translation. As a matter of fact, AI-driven systems can outperform humans in a range of activities such as solving numerical problems, pattern recognition, and retrieving information from a massive number of sources. Nevertheless, such systems are still in their infancy when it comes to abstract reasoning, social interactions, consciousness, or self-awareness, all of which are routine for humans but out of reach for machines — at least so far.
In view of this, it is important to distinguish between different levels of AI. According to Kaplan and Haenlein1, the evolution of AI can be divided into three stages:
- Artificial narrow intelligence: the application of AI to specified tasks.
- Artificial general intelligence: the application of AI to autonomously solve novel problems in multiple fields.
- Artificial super intelligence: the application of AI to any area that can benefit from scientific creativity, social skills and general wisdom.
Most of today’s AI solutions fall into the first category. In this sense, even James Watt’s flyball governor, a speed regulator for his rotary steam engine of 1768, could be considered AI at stage one. Certainly, it was never marketed as such — and the same can be said for the millions of control solutions operating in the power, refining and chemical industries.
AI as a solution
Typically, AI systems not only consist of a brain, or in other words, a sophisticated algorithm; they also must be able to perceive and interact with the world. Vision, hearing, speaking and motion complement the brain and allow AI-based systems to solve real-world problems — tasks very similar to those encountered by process control systems. While sensors measure process values (dependent variables), such as pressure, flow, temperature etc, the controller takes these inputs and calculates the best way to adjust actuators such as valves, dampers etc (independent variables) to meet certain control objectives. In this scenario the controller’s role is that of a brain, running algebraic calculations and making logical decisions.
Why now?
One of the most obvious reasons why AI is gaining ground now is the exponential increase of available computing power. Some of the constraints data scientists had in the past — such as a limited number of neurons in an artificial neural network (ANN) — basically vanished, thus opening the door to leveraging the full potential of deep learning networks. Furthermore, anybody with a laptop and access to a cloud solution can run a training algorithm. This opens the market for new business models such as self-service model training and software as a service (SaaS). This not only democratises AI but reduces engineering requirements on control solutions.
In the process industry, digitisation began in the late 1970s with the widespread introduction of programmable logic controllers (PLCs) and distributed control systems (DCS), which replaced analog controllers. Adding new data points and control features became a programming task, rather than a hardware installation and configuration task. This significantly increased the flexibility of the control process while reducing costs. However, adding more control features led to more complex control structures, which were often difficult to understand and maintain. They also required significant engineering effort and process know-how. The need for a leaner and more transparent control approach arose.
Advanced process steps
Advancements in mathematics and systems theory, and the increasing availability of computer power, enabled the development of more advanced process controls. The mathematical fundamentals behind this process can be traced back to the work of Rudolf Kálmán in the early 1960s2. While differential equations describe the dynamics of a physical system in a kind of ‘cleanroom’ scenario, Kálmán added terms for state disturbance and measurement noise, something inevitable in any real-world application. Moreover, he directly formulated his equations using matrix representation, accounting for multiple differential equations with their respective inputs and outputs. This multi-input, multi-output (MIMO) approach made it possible to calculate an optimal control strategy not only for one actuator at a time, but for many simultaneously.
It turned out that Kálmán’s mathematical solution could also be used to look into the future of a process. In contrast to a simple controller, which only calculates the next optimal step for one variable, it was now possible to look multiple steps ahead into the future for multiple variables. The goal remained the same: to minimise the control error, which is the difference between desired and actual process values. But whereas a simple control is ‘driving by sight’, a forward-looking regulator creates a longer-term plan to act upon.
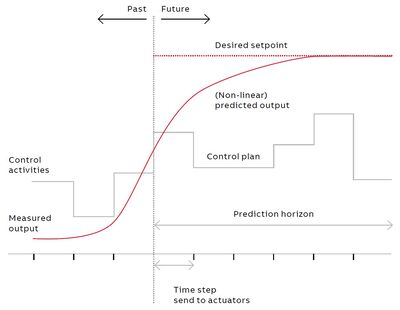
However, as things often do not go according to plan, it became evident that controllers must be able to adjust to changing situations based on feedback from a process. This led to the development of Model Predictive Control (MPC), which generates an optimal control path but triggers only the first step in each iteration. A moment later, once feedback is received, it repeats the process of calculating the optimal path until the desired operating point is reached (Figure 1).
Although these steps have significantly improved many processes, there are multiple areas where process control is still limited.
Real-time feedback
As described above, controllers require feedback from the process they are controlling, otherwise their performance may suffer. This problem intensifies the longer the delay between action and feedback. Specifically, data with large time gaps compared to the actual process might pose issues. This is typically the case for laboratory data covering product properties that cannot be measured continuously or in real time, such as viscosity or flashpoint. Adjustments to a process can be performed only after receiving results from the lab, which, because of the inherent delay, might compromise product quality.
One way to overcome this is to estimate the values of a product’s qualities in real time using machine learning (ML) models, such as artificial neural networks (ANN). Here, the accuracy of the models can be continuously improved with each new lab measurement. Predicted qualities can then be used without delay by the control algorithm to adjust the process. In this configuration, conventional and AI-based control algorithms work hand-in-hand to achieve and maintain desired production goals. This concept can also be applied to processes with long dead times or processes that use sensors that need to be recalibrated regularly and are thus not continuously available.
Adapting to non-linearities
Like most systems in the real world, industrial processes are often non-linear. This results in a systemic discrepancy between the real process and its linear process model. In the context of short time horizons and minor process alterations, the resulting error may be negligible. However, on a larger scale it may affect control performance. Although some non-linearities can be offset through transformation of their associated process data — for instance linearisation of a control valve’s characteristic curve — linearisation is not always perfect and can be costly when dealing with many process variables.
AI techniques, on the other hand, can deal very well with non-linearities. ML models can basically adapt to any non-linear behaviour. While most MPC implementations use a linear approach for modelling, the framework itself makes no assumption about the type of process model used or its linearity. Therefore, non-linear models trained with ML algorithms can also be used to reduce modelling errors. This leads to more accurate control and prevents the controller from getting trapped in minor optimisations.
Identifying the right process behaviour
At the heart of any advanced process control system is a process model. However, the process of identifying the dynamics of a physical system is costly and requires domain know-how and experience.
Traditionally, there are two approaches to model design: a so-called ‘first principles model’, which is based on the design, mechanics and fundamental physics of a system, and a so-called ‘empirical model’, which is based on observations of how a system reacts to stimuli, for example, by means of step-response experiments.
Both approaches can be highly complex, costly, and in some cases — due to the nature of the process — impossible to implement. However, in many cases this burden can be avoided if adequate historical process data is available. During normal plant operation, set-points are regularly changed and disturbances are continuously happening, both triggering reactions in the process, and thus revealing its dynamic behaviour. These footprints can be used by ML algorithms to easily create accurate models. To accomplish this, the data must be representative and thus cannot be randomly picked. For instance, abnormal process behaviour, or periods with missing data must be removed. Doing this manually would be costly, but for an algorithm this is the perfect task. Selecting, segmenting and clustering vast amounts of data is a home run for machine learning.
Conclusion
Process control systems have evolved over time from first principles modelling to proportional integral derivative (PID) loop monitoring, model predictive control, and dynamic optimisation. Today, with the assistance of hardware and machine learning algorithms, it is now possible to complement this with the benefits and opportunities of artificial intelligence.
All in all, it can be said that joining the world of control to that of artificial intelligence can yield significantly improved results in terms of controlling industrial processes. Indeed, the more such hybrid control solutions spread, the more both worlds will converge — an apparently natural process since both share the same theoretical foundations. As this process evolves, continued progress is set to pave the way to the introduction of tomorrow’s fully autonomous production facilities.
1. Kaplan A and Haenlein M 2019, ‘Siri-Siri in my hand, who is the fairest in the Land?’, Business Horizons, vol. 62, no. 1, 2019, pp. 15-25.
2. Kálmán RE 1960, ‘A New Approach to Linear Filtering and Prediction Problems’, Journal of Basic Engineering, vol. 82, no. 1, 1960, pp. 35-45.
Valves, data centres and the invisible infrastructure of Australian industry
If we are serious about making Australian industry both competitive and sustainable, we have to...
Electric actuation: a gamechanger for upstream processes
The electrification of upstream oil and gas processes offers the opportunity to reduce emissions...
Encore Tissue improves plant reliability with new DCS
An Australian toilet paper and paper towel manufacturer needed a modern DCS solution that would...





")
